Abstract
Recent text-to-video diffusion models have achieved impressive progress. In practice, users often desire the ability to control object motion and camera movement independently for customized video creation. However, current methods lack the focus on separately controlling object motion and camera movement in a decoupled manner, which limits the controllability and flexibility of text-to-video models. In this paper, we introduce Direct-a-Video, a system that allows users to independently specify motions for multiple objects as well as camera's pan and zoom movements, as if directing a video. We propose a simple yet effective strategy for the decoupled control of object motion and camera movement. Object motion is controlled through spatial cross-attention modulation using the model's inherent priors, requiring no additional optimization. For camera movement, we introduce new temporal cross-attention layers to interpret quantitative camera movement parameters. We further employ an augmentation-based approach to train these layers in a self-supervised manner on a small-scale dataset, eliminating the need for explicit motion annotation. Both components operate independently, allowing individual or combined control, and can generalize to open-domain scenarios. Extensive experiments demonstrate the superiority and effectiveness of our method.
Method
|
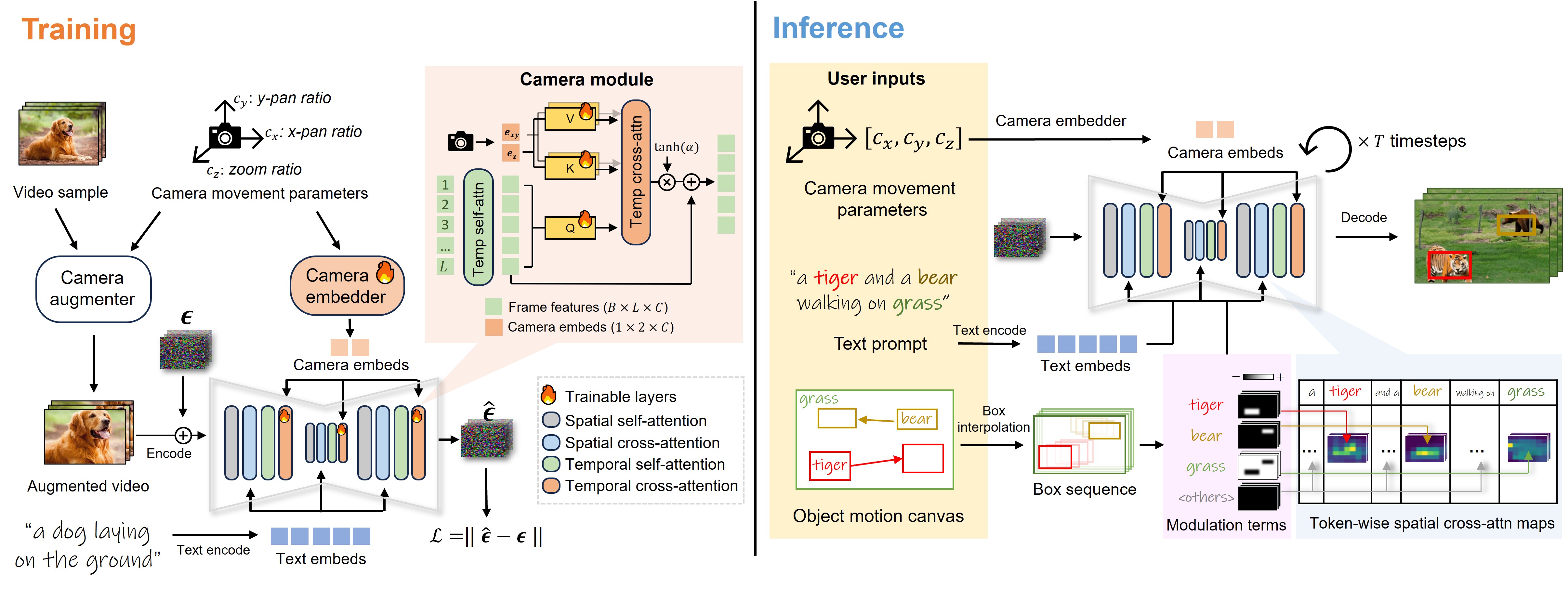
Our framework synthesizes a video that aligns with the user-directed camera movement and object motion. The camera movement is learned in the training stage and the object motion is implemented in the inference stage. Left: During training, we apply augmentation to video samples to simulate camera movement using panning and zooming parameters. These parameters are embedded and injected into newly introduced temporal cross-attention layers as the camera movement conditioning, eliminating the need for camera movement annotation. Right: During inference, along with camera movement, user inputs a text prompt containing object words and associated box trajectories. We use spatial cross-attention modulation to guide the spatial-temporal placement of objects, all without additional optimization. Note that our approach, by independently controlling camera movement and object motion, effectively decouples the two, thereby enabling both individual and joint control. |
||
|
 Camera Movement Control
Camera Movement Control
Basic Camera Movement
Hybrid Camera Movement (X+Y)
Hybrid Camera Movement (X+Z)
 Object Motion Control
Object Motion Control
 Joint Control on Camera Movement and Object Motion
Joint Control on Camera Movement and Object Motion
Static Box + Hybrid Camera Movement
Single Moving Box + Hybrid Camera Movement
Multiple Moving Boxes + Hybrid Camera Movement
BibTeX
@article{yang2024direct,
title={Direct-a-Video: Customized Video Generation with User-Directed Camera Movement and Object Motion},
author={Yang, Shiyuan and Hou, Liang and Huang, Haibin and Ma, Chongyang and Wan, Pengfei and Zhang, Di and Chen, Xiaodong and Liao, Jing},
journal={arXiv preprint arXiv:2402.03162},
year={2024}
}